Transkription und Translation
Die Transkription
Wird ein Protein in der Zelle benötigt, wird von dem entsprechenden Abschnitt des DNA-Moleküls zunächste eine Kopie erzeugt. Die genetische Information wird damit beweglich und kann aus dem Zellkern durch die Kernporen hinaustransportiert werden. Sie kann so zu den Ribosomen, den Orten der Proteinbiosynthese, transportiert werden. Das Transportmolekül für die genetische Information ist eine Ribonukleinsäure (RNA). Da sie die genetische Botschaft (engl. message) überträgt, nennt man sie messenger-RNA oder kurz mRNA. Der Beginn der Transkription erfolgt an einer spezifischen Startsequenz auf der DNA, die vor dem Gen liegt, welches abgeschrieben werden soll. An dieser Stelle bindet die RNA-Polymerase und bewegt sich schrittweise entlang der DNA.Während dieses Vorgangs entwindet sie die DNA und öffnet den Doppelstrang auf einem begrenzten Abschnitt, wodurch die Nukleotide beider Stränge freigelegt werden.
Einer der beiden Stränge fungiert als Vorlage, an der sich die komplementären Basen der RNA anlagern. Dieser Strang wird als Matrizenstrang, codogener Strang oder codierender Strang bezeichnet. Die RNA-Nukleotide werden durch die RNA-Polymerase in Richtung 5'-3' zu einem einzelnen Strang verbunden. Dieser Prozess ermöglicht die Synthese einer RNA-Kopie der genetischen Information und bildet somit die Grundlage für die nachfolgende Proteinbiosynthese.

Abb. 1: Ablauf der Transkription
Nach der Freisetzung aus dem Zellkern durchläuft die mRNA eine Prozessierung, die ihre Struktur und Funktion weiter verfeinert:
- Capping:
Am 5'-Ende der mRNA wird ein Methylguanosin-Cap hinzugefügt. Dieser 5'-Cap dient dem Schutz vor Abbau und erleichtert den Transport aus dem Zellkern. - Polyadenylierung:
Am 3'-Ende der mRNA wird ein Poly-A-Schwanz aus Adenin-Nukleotiden angehängt. Dies fördert die Stabilität der mRNA und erleichtert deren Erkennung und Translation. - RNA-Editing:
In einigen Fällen kann die mRNA durch RNA-Editing zusätzlich modifiziert werden, indem Nukleotide verändert oder hinzugefügt werden, um die genetische Information anzupassen. - RNA-Spleißen:
Introns, nicht-kodierende Abschnitte der mRNA, werden entfernt, und die verbleibenden Exons werden verbunden. Dieser Vorgang, bekannt als Spleißen, erzeugt eine reife mRNA, die nur die kodierenden Abschnitte enthält.

Abb. 2: Überblick über den Prozess der Genexpression
Die Translation
Bei der Translation erfolgt die Umwandlung der Basensequenz der mRNA in eine Aminosäuresequenz. Der genetische Code gibt die Anweisungen dafür, wie die Abfolge der Basen in Aminosäuren übersetzt wird. Eine spezielle Nukleinsäure, die sogenannte transfer-RNA (tRNA), agiert als Verbindungsglied zwischen der Basen- und Aminosäuresequenz. Die tRNA transportiert Aminosäuren aus dem Vorrat im Cytoplasma zu den Ribosomen, wo passende Aminosäuren dann zur Bildung des Polypeptids verknüpft werden. Die tRNA weist eine spezielle räumliche Struktur auf, die für ihre Funktion in der Translation entscheidend ist. Jede t-RNA trägt ein spezifisches Basentriplett (das sogenannte Anticodon), das komplementär zu einem Codon der mRNA ist. Über diese Stelle interagieren t-RNA und mRNA. Eine t-RNA wird von speziellen Enzymen mit einer Aminosäure beladen. Es wird immer die Aminosäure gebunden, für die das Codon kodiert.Initation:
Die Translation findet an den Ribosomen statt. Diese bestehen aus zwei Untereinheiten und bewegen sich entlang der mRNA, um die Basenfolge abzulesen. Ein Ribosom verfügt über drei Bindungsstellen für tRNA-Moleküle.Elongation:
An der P-Stelle bindet die tRNA, die die wachsende Peptidkette trägt. An der A-Stelle bindet die tRNA, an der die nächste Aminosäure in der Kette befestigt ist. An der E-Stelle verlässt die tRNA das Ribosom.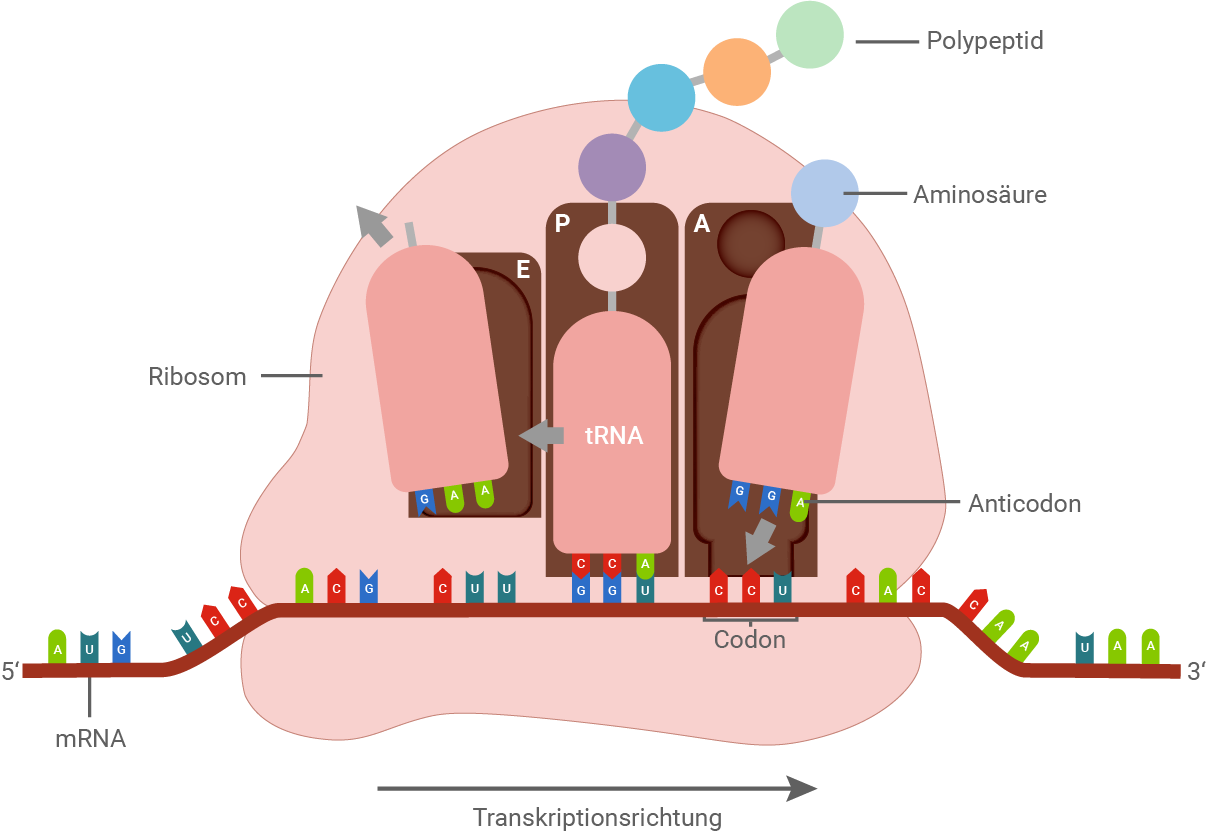
Abb. 3: Ablauf der Translation an den Ribosomen
Termination:
Sobald das Ribosom eine Stoppsequenz erreicht, trennt sich die Peptidkette von der tRNA, und das Ribosom zerfällt wieder in seine beiden Untereinheiten. Die freigesetzte Polypeptidkette im Cytoplasma faltet sich dann zu einem fertigen Protein.Verwendung der Code-Sonne
Die mRNA stellt die komplementäre Basensequenz zum codogenen Strang der DNA dar. Allgemein betrachtet kann man die mRNA als einen „Boten“ der DNA verstehen. Durch die Basentripletts der mRNA können Aminosäuresequenzen direkt abgelesen werden. Die Code-Sonne fungiert als eine Art Übersetzungshilfe, die es ermöglicht, die entsprechende Aminosäure zu einem Basentriplett zu identifizieren oder Aminosäurensequenzen den Basentripletts der mRNA zuzuordnen.- Zu Beginn richtest du deine Aufmerksamkeit auf den innersten Kreis der Code-Sonne, der in vier Abschnitte untergliedert ist. In diesem Schritt liegt deine Aufgabe darin, die Base zu erkennen, mit der das Basentriplett seinen Anfang nimmt.
- Als nächstes analysierst du, welche Base sich an zweiter Stelle des Basentripletts befindet.
- Jetzt gilt es zu ermitteln, welche Base sich am Ende des Basentripletts befindet. Du wechselst vom zweiten Ring der Code-Sonne zum dritten Ring und suchst das Feld mit der entsprechenden Base.
- Im äußersten Ring sind jetzt sämtliche Aminosäuren aufgeführt, die durch die Codierung der mRNA entstehen können. Einige von ihnen treten sogar mehrmals auf und sind mit einem Sternchen gekennzeichnet.
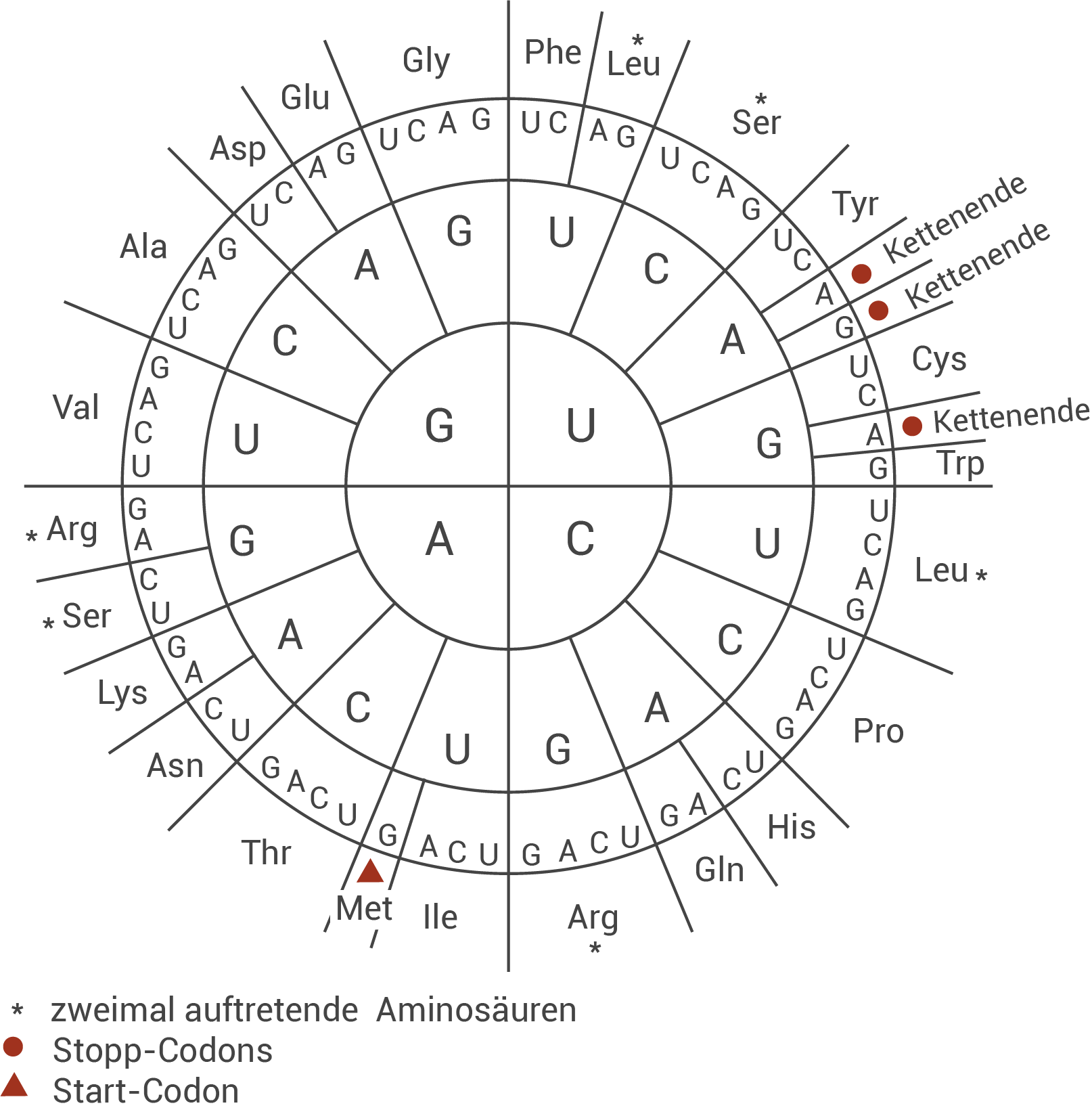
Abb. 4: Code-Sonne